




单列集合 Collection
> 💡 Tips:Collection 代表单列集合,每个元素(数据)只包含一个值; > > 应对不同的业务场景需要,衍生很多实现类; > > 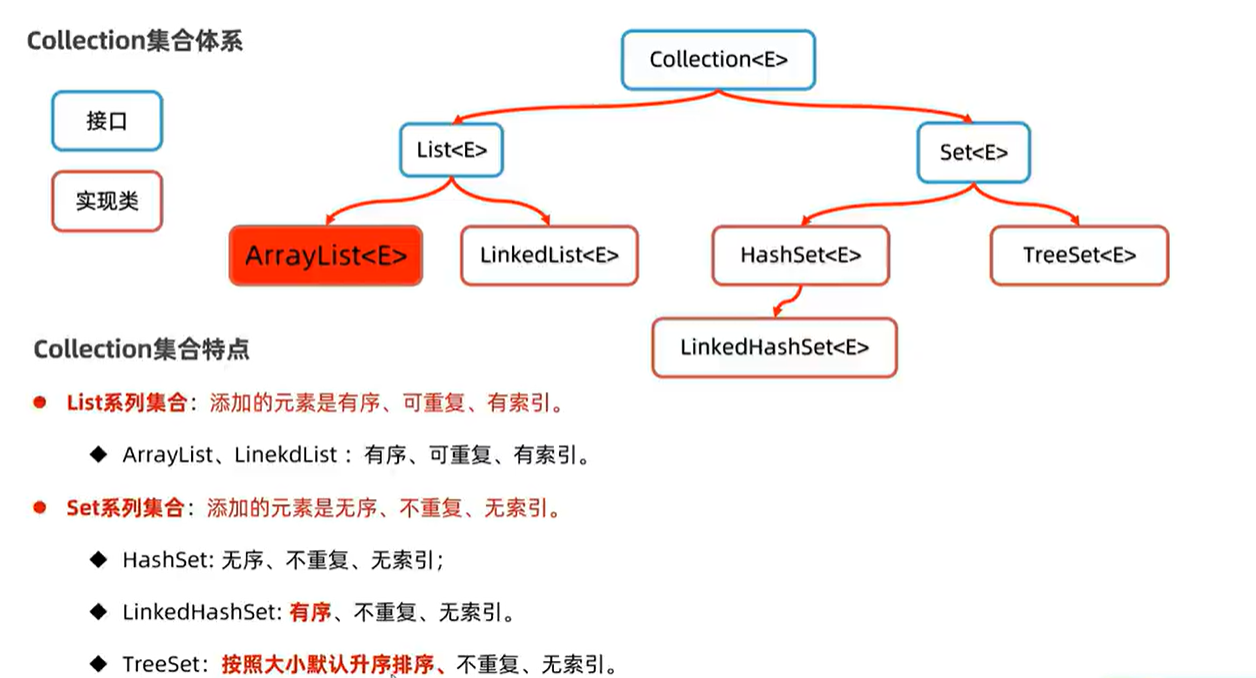 >Collection集合的常见方法

遍历集合的方法
1. 迭代器遍历; 2. 增强for循环遍历; 3. lambda表达式遍历;

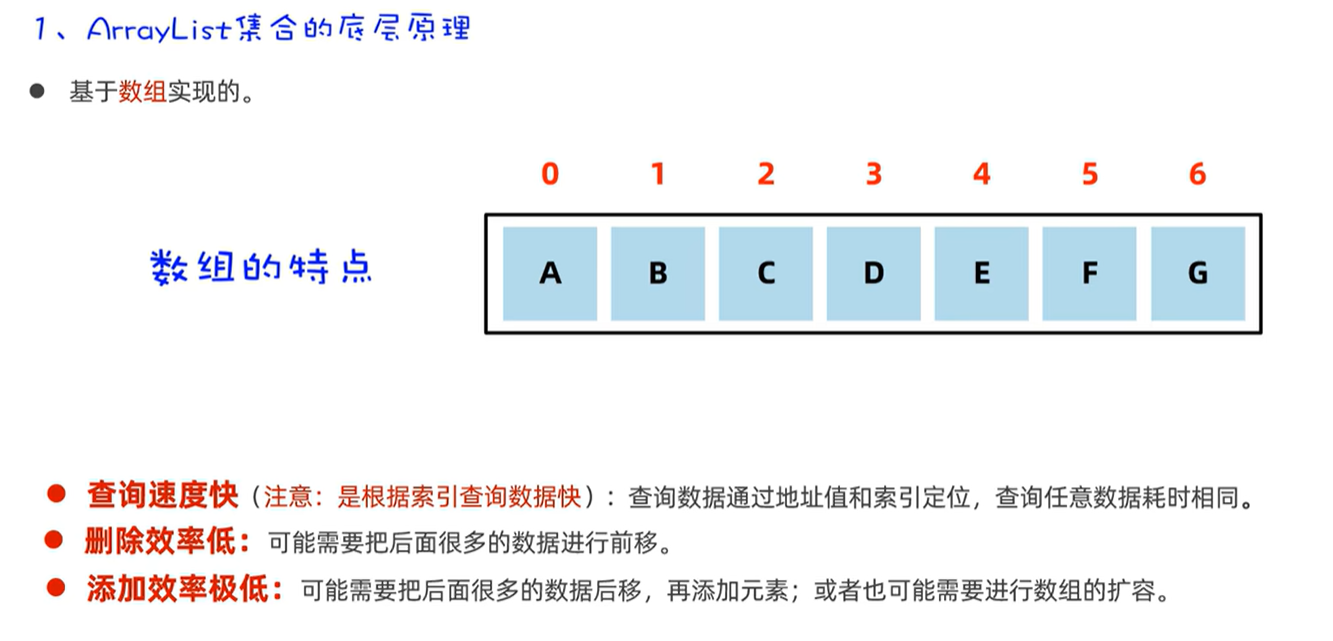
List系列集合:有序、可重复,有索引
ArrayList:基于数组,查询快,增删慢
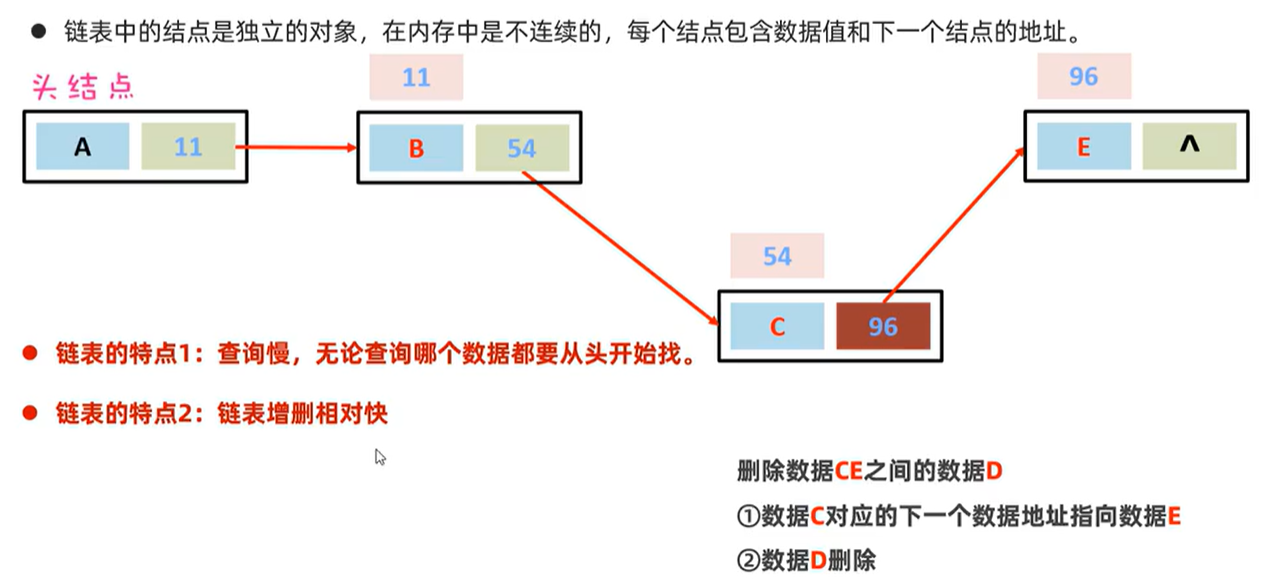
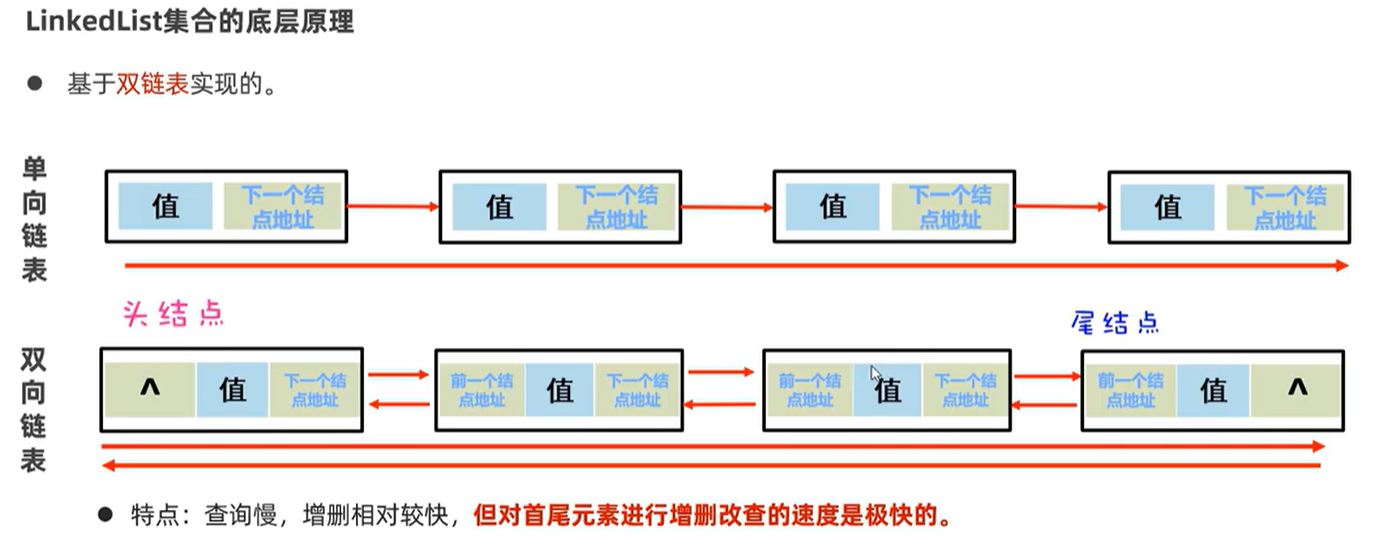
LinkedList:基于双链表,查询慢,增删快
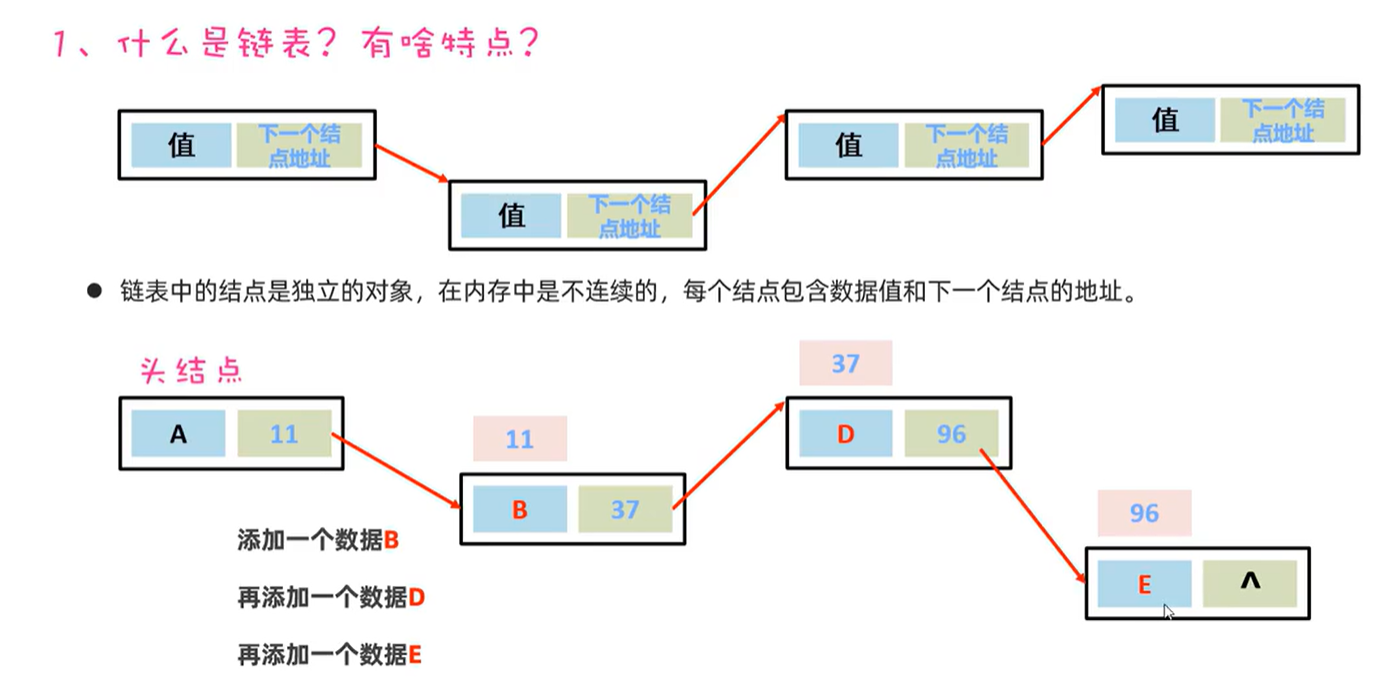

Set:不重复、无索引
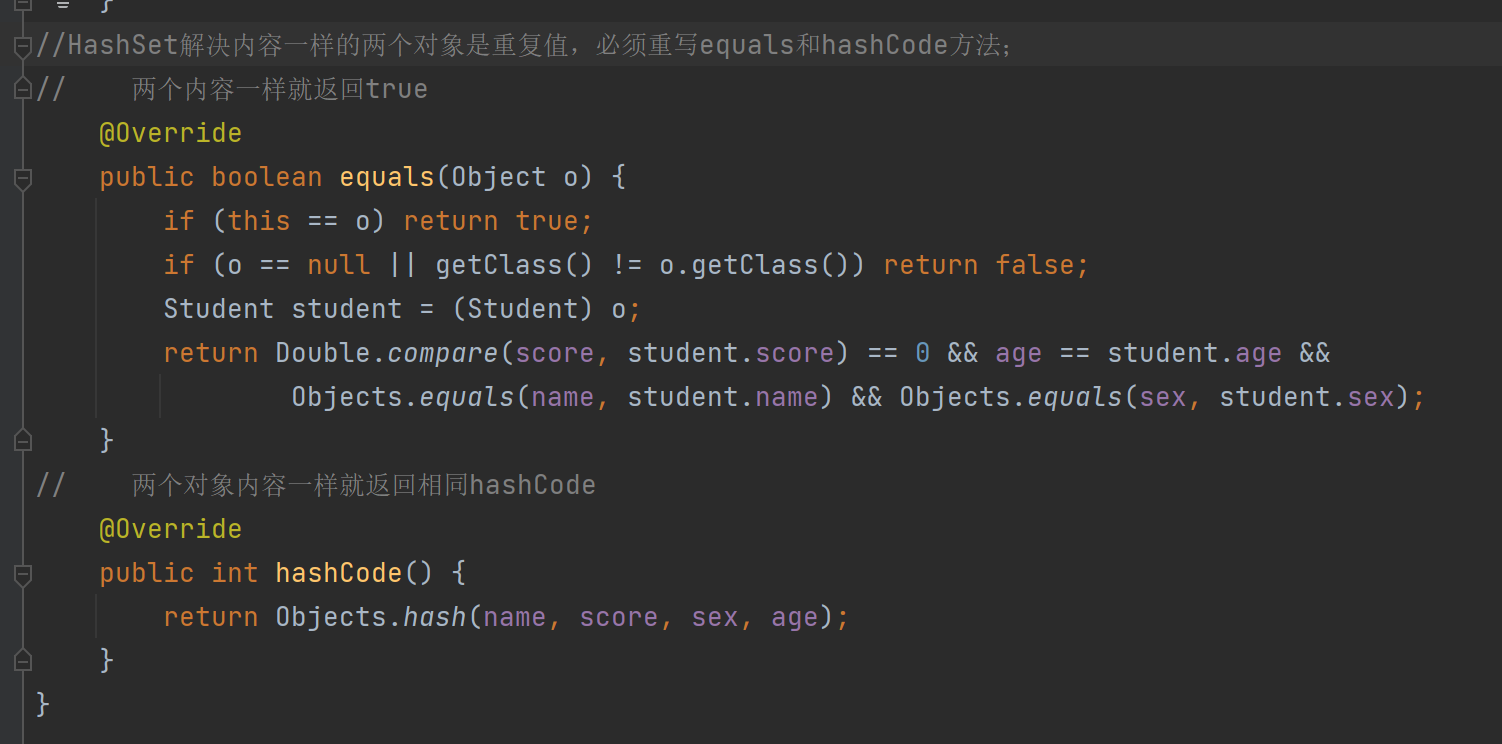
哈希值
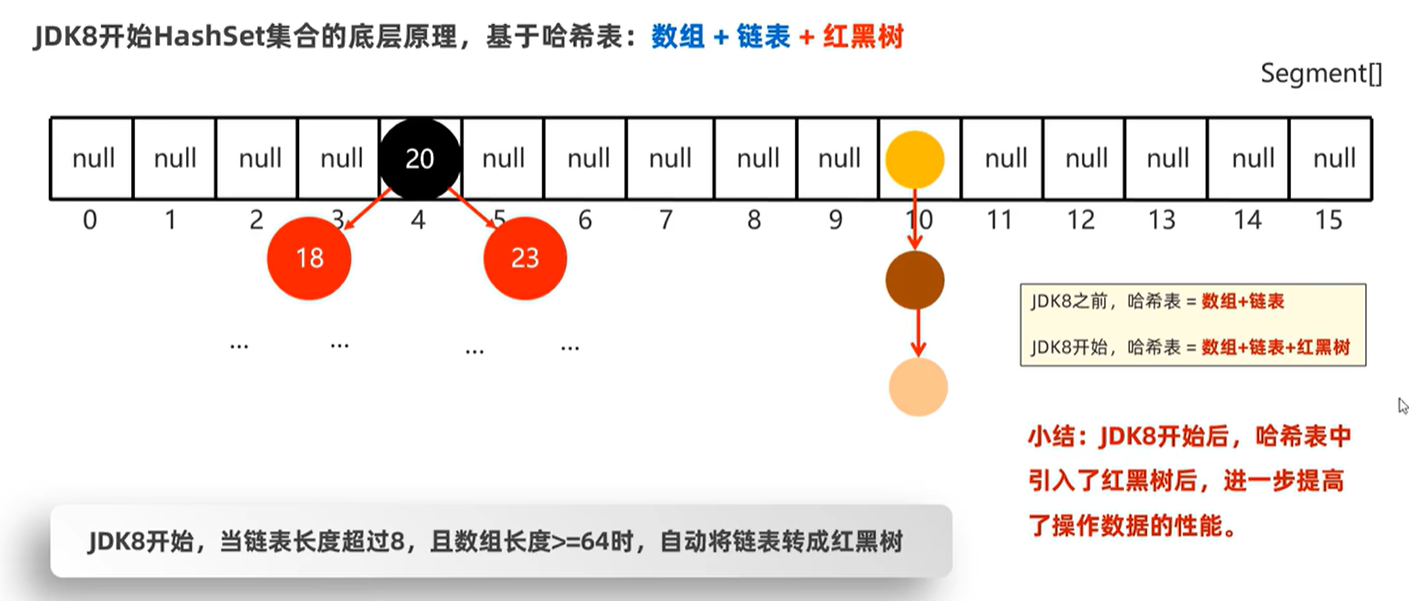
HashSet:基于哈希表:数组+链表+红黑树;增删改查都较快
LinkedHashSet:基于哈希表:数组+双链表+红黑树;有序、不重复、无索引;
TreeSet:不重复、无索引、可排序(默认升序,可降序,利用红黑树实现)

集合的并发修改异常:
遍历删除集合的数据会出现bug,会漏删数据;增强for循环、 lambda表达式forEach都无法避免,只能使用迭代器Iterator;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class ExcepctionListTest01 {
public static void main(String[] args) {
List<String> ls = new ArrayList<>();
ls.add("白骨精");
ls.add("孙悟空");
ls.add("李玉刚");
ls.add("李四");
ls.add("李二牛");
ls.add("李世民");
ls.add("小李子");
ls.add("李元霸");
ls.add("唐三藏");
ls.add("白骨精");
System.out.println(ls);
for (String l : ls) {
System.out.println(l);
}
System.out.println("---------------");
// 需求:找出集合中全部带李的名字,并从集合中删除;
for (String l : ls) {
if(l.contains("李")){
continue;
}
System.out.println(l);
}
// 遍历集合的数据会出现bug,会漏删数据;
// System.out.println("---------------");
// Iterator<String> it= ls.iterator();
//
// while (it.hasNext()){
// String name =it.next();
// if(name.contains("李")){
// ls.remove(name);
// }
// System.out.println(ls);
// }
// System.out.println("============");
// for (int i = 0; i < ls.size(); i++) {
// String name = ls.get(i);
// if(name.contains("李")){
// ls.remove(name);
//// System.out.println(ls);
// i--;
// }
// }
// for (String l : ls) {
// System.out.println(l);
// }
System.out.println("==========");
Iterator<String> it = ls.iterator();
while (it.hasNext()){
String name = it.next();
if(name.contains("李")){
it.remove();
}
}
for (String l : ls) {
System.out.println(l);
}
}
}
可变参数:test(int...nums)
Collections
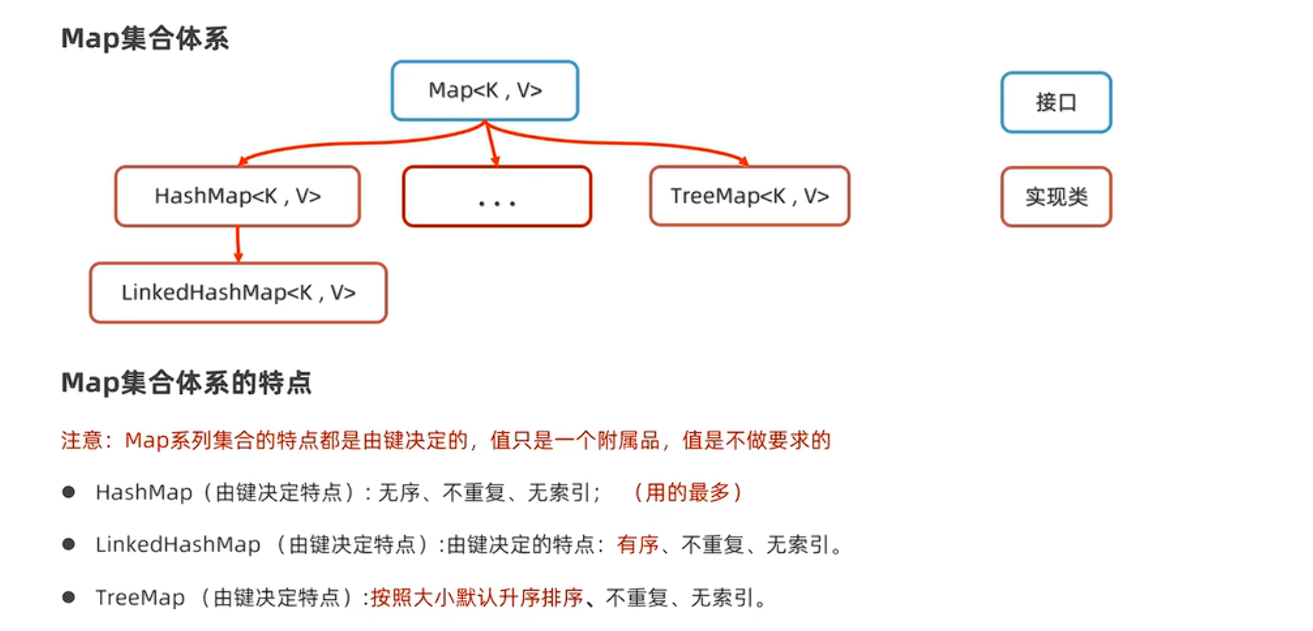
双列集合Map(key:value)键值对(key不能重复)
Map集合的遍历方式
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTest03 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("one",1);
map.put("two",2);
map.put("three",3);
map.put("four",4);
map.put("five",5);
//使用增强for循环遍历map
for(Map.Entry<String,Integer> entry:map.entrySet()){
System.out.println(entry.getKey()+" "+entry.getValue());
}
//遍历key
for(String key:map.keySet()){
System.out.println(key);
}
//遍历value
for(Integer value:map.values()){
System.out.println(value);
}
System.out.println("--------------------");
//使用foreach遍历
map.forEach((key,value)-> System.out.println(key+" "+value));
System.out.println("---------------");
//使用迭代器遍历
Set<Map.Entry<String,Integer>> entries = map.entrySet();
Iterator<Map.Entry<String,Integer>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String,Integer> entry = iterator.next();
System.out.println(entry.getKey()+" "+entry.getValue());
}
System.out.println("--------------------");
//使用for循环遍历
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println(key+" "+map.get(key));
}
}
}
HashMap:基于哈希表:数组+链表+红黑树;增删改查都较快

LinkedHastMap:基于哈希表:数组+双链表+红黑树;有序、不重复、无索引;
TreeMap:不重复、无索引、可排序(默认升序,可降序,利用红黑树实现)
集合的嵌套
```java import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map;public class MapDemo4 { public static void main(String[] args) { /**
集合的嵌套
需求 要求在程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息。 江苏省=南京市,扬州市,苏州市,无锡市,常州市 湖北省=武汉市,孝感市,十堰市,宜昌市,鄂州市 河北省=石家庄市,唐山市,邢台市,保定市,张家口市 */
Map<String, List<String>> map=new HashMap<>(); List<String> list1=List.of("南京市","扬州市","苏州市","无锡市","常州市"); List<String> list2=List.of("武汉市","孝感市","十堰市","宜昌市","鄂州市"); List<String> list3=List.of("石家庄市","唐山市","邢台市","保定市","张家口市"); map.put("江苏省",list1); map.put("湖北省",list2); map.put("河北省",list3); System.out.println(map); System.out.println(map.get("湖北省"));
// System.out.println("------------------------------------");
// List
System.out.println("------------------------------------");
for (String s : map.keySet()) {
System.out.println(s);
System.out.println("-------");
for (String i : map.get(s)) {
System.out.println(i);
}
System.out.println("===============================");
}
}
}
<h1 id="uHTx3">Stream流操作集合或数组</h1>

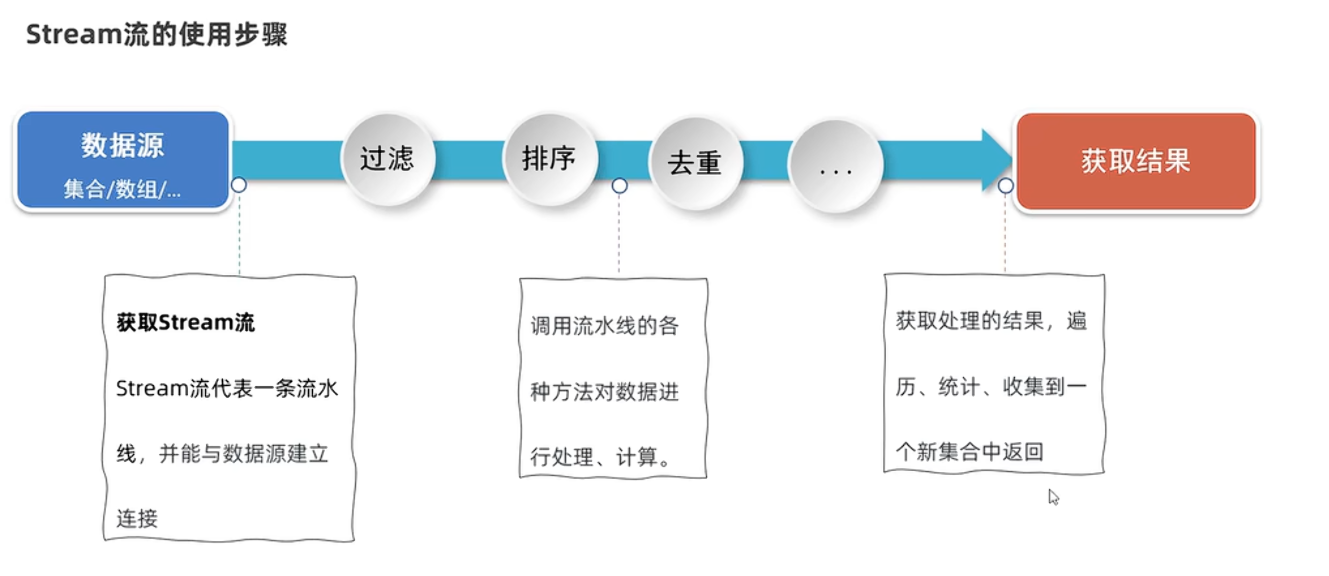
<h2 id="h8ft9">1、Stream流对集合的操作</h2>
```java
import java.util.*;
import java.util.stream.Stream;
public class StreamTest02 {
public static void main(String[] args) {
// 1、如何获取List集合的Stream流;
List<String> list = new ArrayList<>();
Collections.addAll(list,"张三", "李四", "王五", "赵六", "钱七");
Stream<String> stream = list.stream();
stream.forEach(System.out::println);
System.out.println("-------------");
// 2、如何获取set集合的Stream流;
Set<String> set = new HashSet<>();
Collections.addAll(set,"张三", "李四", "王五", "赵六", "钱七");
Stream<String> stream1 = set.stream();
stream1.filter(s->s.contains("王")).forEach(System.out::println);
System.out.println("-------------");
// 3、如何获取map集合的Stream流;
Map<String, Double> map = new HashMap<>();
map.put("张三", 18.8);
map.put("李四", 20.0);
map.put("王五", 22.4);
map.put("赵六", 24.3);
map.put("赵灵儿", 24.2);
map.put("赵老六", 25.5);
map.put("钱七", 26.2);
// Stream<String> stream2 = map.entrySet().stream().map(entry -> entry.getKey());
Stream<String> stream2 = map.keySet().stream();
stream2.filter(s->s.length()==2).forEach(System.out::println);
System.out.println("-----------------------");
// Stream<Double> stream3 = map.entrySet().stream().map(entry -> entry.getValue());
Stream<Double> stream3 = map.values().stream();
stream3.filter(s->s>=21.0).forEach(System.out::println);
System.out.println("-----------------------");
// Stream<Map.Entry<String, Double>> stream4 = map.entrySet().stream();
// stream4.filter(s->s.getKey().contains("赵")&&s.getValue()>=24.3).forEach(entry -> System.out.println(entry.getKey() + ":" + entry.getValue()));
Set<Map.Entry<String, Double>> set1 = map.entrySet();
set1.stream().filter(s->s.getKey().contains("赵")&&s.getValue()>=24.3).forEach(entry -> System.out.println(entry.getKey() + ":" + entry.getValue()));
System.out.println("-----------------------");
// 4、如何获取数组的Stream流;
String[] arr = {"张三", "李四", "王五", "赵六", "钱七"};
Stream<String> stream5 = Arrays.stream(arr);
Stream<String> stream6 = Arrays.stream(arr, 1, 3);
Stream<String> stream7 = Stream.of(arr);
stream5.forEach(System.out::println);
System.out.println("-----------------------");
stream6.forEach(System.out::println);
System.out.println("-----------------------");
stream7.forEach(System.out::println);
}
}
2、Stream流的中间方法
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamTest03 {
public static void main(String[] args) {
List<Double> list=List.of(1.70,1.70,1.80,1.78,1.75,1.65);
//1.找出list中大于等于1.70的所有元素
list.stream().filter(d->d>=1.70).sorted().forEach(System.out::println);
System.out.println("-----------");
//2.找出list中大于等于1.70的所有元素,并计算它们的平均值
list.stream().filter(num -> num >= 1.70)
.mapToDouble(Double::doubleValue)
.average()
.ifPresent(System.out::println);
System.out.println("-----------");
List<Student> students=new ArrayList<>();
students.add(new Student("蜘蛛精",20,1.88));
students.add(new Student("蜘蛛精",20,1.90));
students.add(new Student("唐三藏",28,1.80));
students.add(new Student("牛魔王",18,1.78));
students.add(new Student("孙悟空",26,1.75));
students.add(new Student("猪八戒",23,1.65));
students.add(new Student("沙悟净",30,1.58));
students.add(new Student("白龙马",34,1.85));
students.add(new Student("太上老君",32,1.57));
students.add(new Student("二郎神",35,1.75));
//1.找出年龄大于20且小于30的学生,并按年龄降序,sored()默认升序;
students.stream().filter(s->s.getAge()>20&&s.getAge()<33)
.sorted((o1, o2) -> o2.getAge()- o1.getAge())
.forEach(System.out::println);
System.out.println("------------");
//2.找出年龄大于20且小于30的学生,并按身高升序,取前3个
students.stream().filter(s->s.getAge()>20&&s.getAge()<33)
.sorted((o1, o2) -> Double.compare(o2.getHeight()-o1.getHeight(),0))
.limit(3)
.forEach(System.out::println);
System.out.println("------------");
// 3.取出身高最矮的两个学生;
students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight()-o1.getHeight(),0))
.skip(students.size()-2)
.forEach(System.out::println);
System.out.println("------------");
// 4.找出身高最高的学生的姓名和身高;
Optional<Student> max=students.stream().max((o1, o2) -> Double.compare(o2.getHeight()-o1.getHeight(),0));
System.out.println(max);
System.out.println("------------");
// 5.找出身高最高超过1.75的学生的姓名;要求去除重复的名字再输出;
students.stream().filter(s->s.getHeight()>1.75)
// .map(s->s.getName())
.map(Student::getName)
.distinct()
.forEach(System.out::println);
System.out.println("------------");
// 6.找出身高最高超过1.75的学生的姓名和年龄;要求去除重复的名字再输出;
students.stream().filter(s->s.getHeight()>1.75)
.sorted((o1, o2) -> o2.getAge()-o1.getAge())
.map(s->s.getName()+":"+s.getAge())
.distinct()
.forEach(System.out::println);
System.out.println("------------");
// 7.合并两个Stream流;
Stream<String> s = Stream.of("abc","def","ghi","abc","def","ghi");
Stream<String> ds = Stream.of("abc","b", "e", "f", "ghi");
Stream<String> concat = Stream.concat(s, ds);
concat.distinct().forEach(System.out::println);
}
}
3、Stream流常见的终结方法

import java.util.*;
import java.util.stream.Collectors;
public class StreamTest04 {
public static void main(String[] args) {
List<Student> students=new ArrayList<>();
students.add(new Student("蜘蛛精",20,1.88));
students.add(new Student("蜘蛛精",20,1.90));
students.add(new Student("唐三藏",28,1.80));
students.add(new Student("牛魔王",18,1.78));
students.add(new Student("孙悟空",26,1.75));
students.add(new Student("猪八戒",23,1.65));
students.add(new Student("沙悟净",30,1.58));
students.add(new Student("白龙马",34,1.85));
students.add(new Student("太上老君",32,1.57));
students.add(new Student("二郎神",35,1.75));
//1、请计算出身高超过168的学生有几人;
long a =students.stream().sorted((s1,s2)->Double.compare(s2.getHeight(),s1.getHeight())).count();
System.out.println(a);
//2、请找出身高最高的学生对象并输出;
students.stream().sorted((s1,s2)->Double.compare(s2.getHeight()-s1.getHeight(),0))
// .skip(students.size()-1)
.max((s1,s2)->Double.compare(s1.getHeight()-s2.getHeight(),0))
.ifPresent(System.out::println);
//3、请找出身高最矮的学生对象,并输出;
students.stream().sorted((s1,s2)->Double.compare(s2.getHeight()-s1.getHeight(),0))
// .limit(1)
.min((s1,s2)->Double.compare(s1.getHeight()-s2.getHeight(),0))
.ifPresent(System.out::println);
//4、请找出身高超过175的学生对象,并放到一个新List集合中去返回;
List<Student> list = students.stream().filter(s -> s.getHeight() > 1.75).collect(Collectors.toList());
list.forEach(System.out::println);
//5、请找出身高超过175的学生对象,并放到一个新Set集合中去返回;
Set<Student> list2 = students.stream().filter(m -> m.getHeight() > 1.75).collect(Collectors.toSet());
list2.forEach(System.out::println);
//6、请找出身高超过175的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回;
Map<String,Double> map = students.stream().filter(s -> s.getHeight() > 1.75)
.collect(Collectors.toMap(item -> item.getName(),
item -> item.getHeight(),
(value1, value2) -> value2));
map.forEach((k,v)-> System.out.println(k+"\t"+v));
/**
* 在使用Java 8的Stream API处理流数据时,如果遇到重复的键(key),可以通过Collectors.toMap()方法的不同重载版本来解决。以下是几种常用的解决方式:
* 使用合并函数:当遇到重复键时,通过提供一个合并函数来决定如何合并这两个值。合并函数接受两个参数,分别代表重复键对应的两个值,返回合并后的结果。
* 选择第一个或最后一个值:如果重复键出现时,可以选择保留第一个出现的值,或者最后一个出现的值。这可以通过在合并函数中直接返回第一个参数或第二个参数来实现。
* 指定默认值:如果重复键出现时,也可以选择返回一个默认值。这需要在合并函数中进行相应的逻辑处理,例如返回null或特定的默认对象。
* 自定义合并逻辑:根据具体业务需求,可以编写自定义的合并逻辑。例如,如果值是数值类型,可以通过加法或其他运算来合并;如果是集合类型,可以进行集合的合并操作。
* 使用专门的Map构造器:在某些情况下,可能需要将结果收集到特定类型的Map中,如TreeMap或LinkedHashMap。这时可以使用带有mapSupplier参数的toMap方法重载版本,提供自定义的Map构造器。
* 避免键的重复:在对数据进行处理前,可以通过过滤或其他方式确保不会出现重复的键。这需要在数据进入流处理之前进行预处理。
* 使用groupingBy:如果需要将重复键的所有值收集起来,可以使用Collectors.groupingBy方法,这将自动处理重复键的情况,并将所有相同键的值收集到一个列表或其他集合中。
* 错误处理:如果确实希望在出现重复键时抛出异常,可以使用只有两个参数的toMap方法重载版本,并在出现异常时进行适当的错误处理。
*/
//7、请找出身高超过175的学生对象,并把学生对象存入到一个数组返回;
Object[] arr =students.stream().filter(s -> s.getHeight() > 1.75).toArray();
for (Object o : arr) {
System.out.println(o);
}
//8、请找出身高超过175的学生对象,并把学生对象的名字和身高,存入到学生类型的数组中返回;
Student[] arr2 = students.stream().filter(s -> s.getHeight() > 1.75).toArray(Student[]::new);
System.out.println(Arrays.toString(arr2));
}
}
📚 推荐阅读
- wx群聊总结助手:一个基于人工智能的微信群聊消息总结工具,支持多种AI服务,可以自动提取群聊重点内容并生成结构化总结
- 历时两周半开发的一款加载live2模型的浏览器插件
- PySide6+live2d+小智 开发的 AI 语音助手桌面精灵,支持和小智持续对话、音乐播放、番茄时钟、书签跳转、ocr等功能
- github优秀开源作品集


评论区